Outils vidéo IA pour OnlyFans : Text-to-Video vs Image-to-Video expliqués
La vidéo est le format de contenu qui progresse le plus vite sur OnlyFans. Ce guide explique comment fonctionnent les outils vidéo IA T2V et I2V, quand utiliser chacun, et comment générer votre première vidéo sur OFGenerator.

Les images construisent votre catalogue. La vidéo construit vos revenus.
Les créateurs qui ajoutent de la vidéo à leur OnlyFans rapportent systématiquement une meilleure rétention des abonnements, plus de pourboires et de meilleures performances sur le contenu pay-per-view. La vidéo crée un sentiment de présence et de mouvement que les images statiques ne peuvent tout simplement pas égaler — et les abonnés paient un premium pour ça.
Le problème a toujours été la production. Filmer, éclairer, monter et rendre de la vidéo est chronophage, techniquement exigeant et coûteux à grande échelle. La génération vidéo par IA résout ce problème.
En 2026, vous pouvez générer des clips vidéo courts à partir d'une description textuelle ou animer votre image d'modèle — sans caméra, sans logiciel de montage, sans équipe de production. Ce guide explique comment les deux approches fonctionnent et quand utiliser chacune.
Comment fonctionne le Text-to-Video
Le text-to-video (T2V) génère un clip vidéo entièrement à partir d'un prompt textuel, sans contrainte d'identité. Il ne s'agit pas de mettre en scène un personnage spécifique — vous créez une scène, une atmosphère, un concept. L'IA a toute liberté créative.
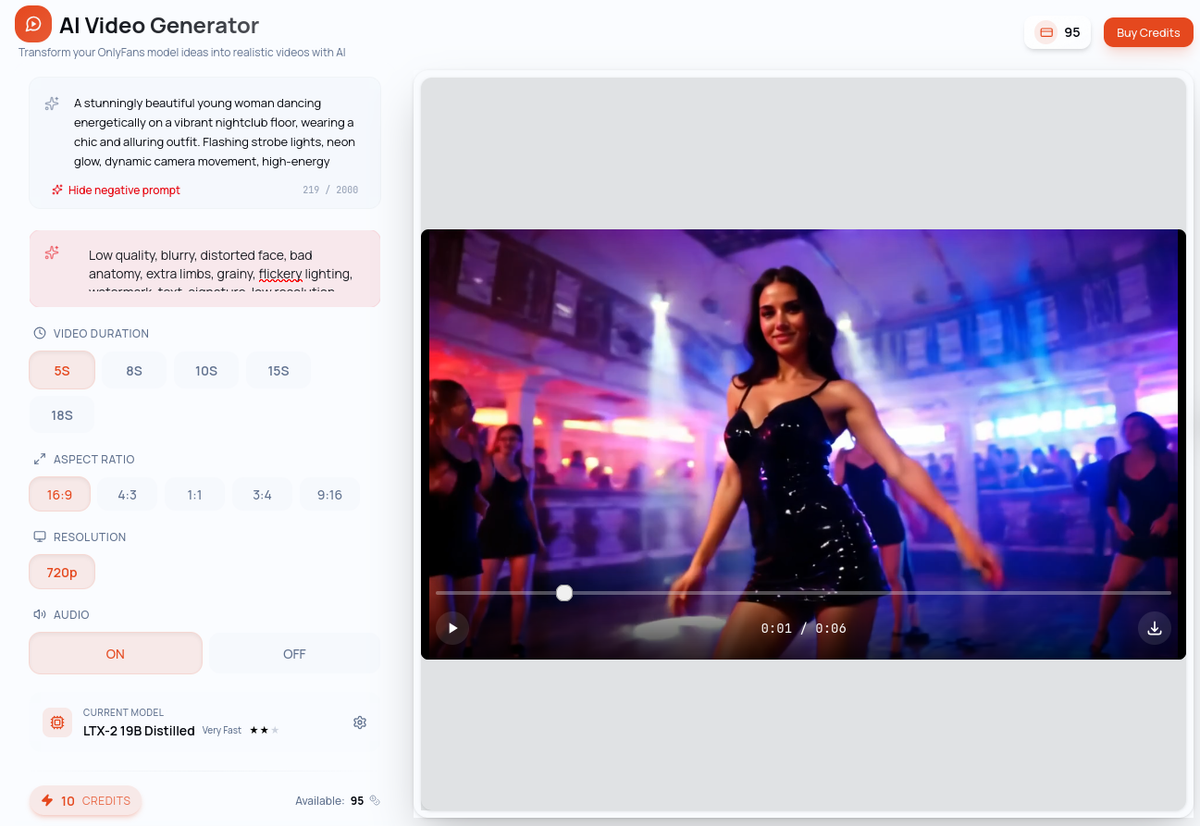
Vous décrivez ce que vous voulez voir : le décor, le mouvement, l'ambiance, le style visuel. L'IA génère un clip correspondant à votre description à partir de zéro.
Exemple de prompt : "Une chambre ensoleillée en début de matinée, lumière douce filtrant à travers des rideaux blancs, légère brise animant le tissu, atmosphère chaude et intime, style cinématographique, mouvement de caméra fluide"
Idéal pour : Le contenu atmosphérique, les scènes créatives, les arrière-plans, et tout contenu où vous n'avez pas besoin qu'un visage ou une identité spécifique apparaisse.
Caractéristique clé : Aucun modèle requis. Le T2V vous donne une liberté créative totale — mais sans ancre d'identité, vous ne pouvez pas garantir un personnage cohérent d'un clip à l'autre.
Comment fonctionne l'Image-to-Video
L'image-to-video (I2V) génère un clip vidéo à partir d'une image de référence — votre modèle. L'IA utilise cette image comme ancre visuelle et l'anime, préservant l'identité de votre personnage tout au long du clip. C'est l'équivalent vidéo de l'Image-to-Image : la même personne, dans une nouvelle scène.
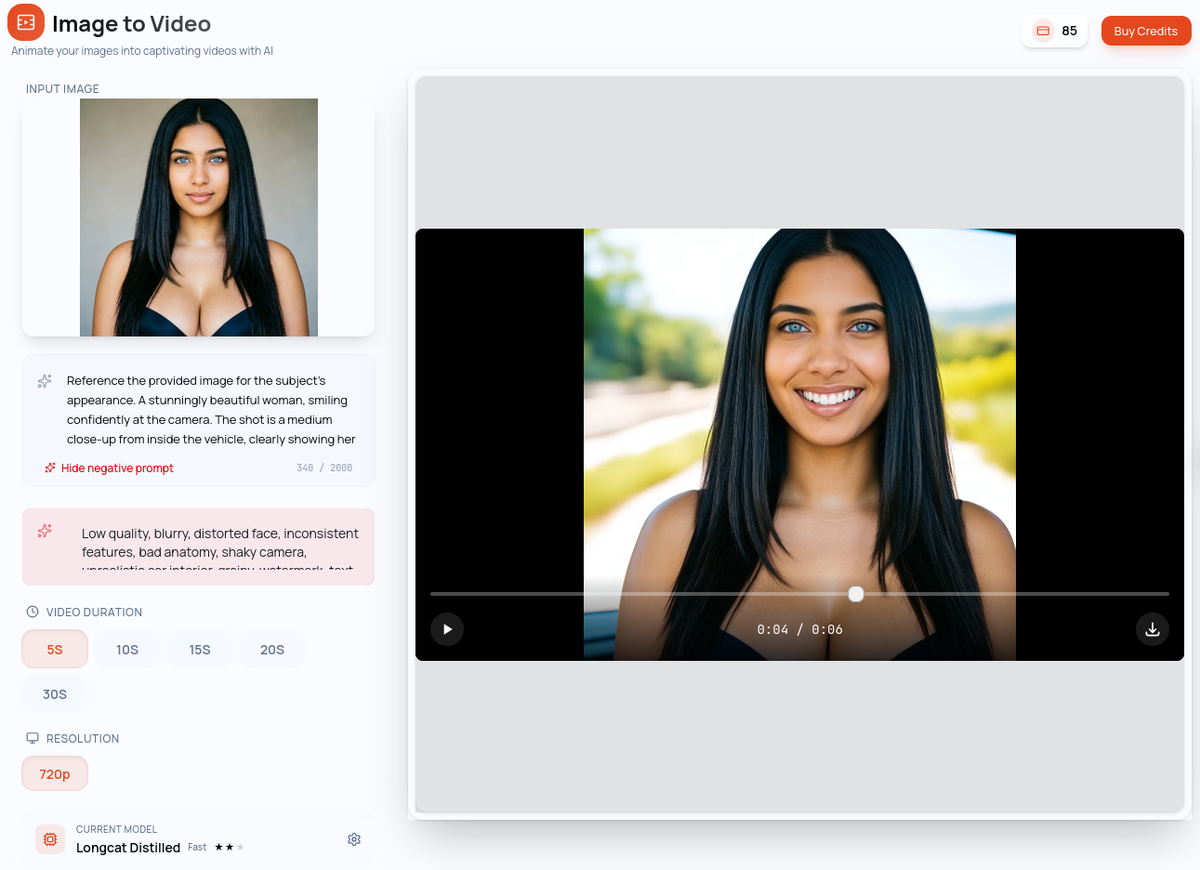
Vous fournissez votre image d'modèle et rédigez un prompt décrivant le mouvement et l'atmosphère souhaités. L'IA donne vie à votre personnage.
Exemple de prompt avec image de référence : "Mouvement de respiration lent et subtil, cheveux bougeant doucement dans une légère brise, éclairage chaud et doux, atmosphère intime et détendue"
Idéal pour : Tout le contenu catalogue mettant en scène votre personnage — teasers, clips pay-per-view, contenu de profil. Partout où votre modèle doit apparaître.
Avantage clé : L'identité de votre modèle est préservée tout au long de la génération. Le visage, le look, la marque visuelle — tout reste cohérent avec votre personnage établi.
T2V vs I2V : quand utiliser lequel
Le choix est simple une fois que vous comprenez la différence fondamentale :
Utilisez le Text-to-Video quand vous créez du contenu qui n'a pas besoin de mettre en scène votre personnage spécifique — scènes atmosphériques, arrière-plans, concepts créatifs, ou contenu expérimental.
Utilisez l'Image-to-Video quand votre modèle doit apparaître dans la vidéo. C'est votre outil standard pour le contenu catalogue, les teasers, et tout clip où la cohérence d'identité est importante.
En pratique, la majorité de votre contenu catalogue utilisera l'I2V. Le T2V est précieux pour l'exploration créative, le contenu complémentaire et la création de pièces atmosphériques qui accompagnent votre contenu principal.
Comparaison rapide
Text-to-Video — Entrée : prompt textuel uniquement | Identité : sans objet | À utiliser quand : aucune contrainte de personnage
Image-to-Video — Entrée : image d'modèle + prompt | Identité : élevée, préserve votre modèle | À utiliser quand : votre personnage doit apparaître
Étape par étape : générez votre première vidéo sur OFGenerator
Étape 1 : Choisissez votre module
Text-to-Video : Aucun modèle requis. Rédigez votre prompt pour décrire la scène, le mouvement, l'ambiance et le style. L'IA génère librement.
Image-to-Video : Sélectionnez votre image d'modèle comme référence. Rédigez un prompt décrivant le mouvement et l'atmosphère souhaités. L'IA anime votre personnage.
Étape 2 : Rédigez votre prompt
Pour les deux modules, un bon prompt vidéo comporte les mêmes quatre composantes qu'un prompt image — sujet ou scène, décor, ambiance/éclairage, style — avec un élément supplémentaire : le mouvement.
Décrivez ce qui bouge et comment. "Lent et doux mouvement de tête" produit des résultats très différents de "marcher à travers la pièce". Commencez par des mouvements simples et subtils pour des résultats plus fiables.
Étape 3 : Sélectionnez votre modèle et générez
Le T2V et l'I2V disposent chacun de leur propre sélection de modèles indépendante. Choisissez un modèle plus rapide pour les ébauches et l'exploration, un modèle de qualité pour le contenu final à publier. La génération vidéo prend plus de temps que les images — tenez-en compte dans votre workflow.
Étape 4 : Évaluez et itérez
Examinez attentivement le résultat : Le mouvement semble-t-il naturel ? L'identité est-elle cohérente avec votre modèle (pour l'I2V) ? Le clip est-il utilisable tel quel ?
De petits ajustements de prompt — ralentir le mouvement, simplifier l'action, modifier la description de l'éclairage — produisent souvent des résultats significativement meilleurs. Itérez jusqu'à ce que le clip atteigne votre standard.
Limitations à connaître
Durée. Les clips vont de 5 à 30 secondes selon le modèle et les paramètres. Ils fonctionnent mieux comme teasers, contenu en boucle ou pièces complémentaires plutôt que comme vidéos longues.
Les mouvements simples fonctionnent mieux. Les mouvements complexes en plusieurs étapes sont plus difficiles à rendre de façon convaincante. Commencez par des animations subtiles — respiration, mouvement de cheveux, panoramiques lents — et progressez à partir de là.
Temps de génération. La génération vidéo prend considérablement plus de temps que les images. Planifiez vos sessions de génération en conséquence, surtout en batch.
Variation d'identité en T2V. Sans image de référence, l'IA n'a pas d'ancre de personnage. N'utilisez pas le T2V quand la cohérence visuelle avec votre modèle est importante.
Conseils pour de meilleurs résultats vidéo
Commencez par des mouvements lents et simples. Les animations subtiles surpassent systématiquement les séquences d'action complexes. Elles paraissent plus naturelles et se génèrent plus facilement.
Utilisez vos meilleures images pour l'I2V. La qualité de votre image de référence impacte directement le résultat. Des images nettes et bien éclairées produisent de meilleurs résultats que des références floues ou peu contrastées.
Décrivez le mouvement explicitement dans votre prompt. Ne décrivez pas seulement la scène — décrivez ce qui bouge et comment. Des descriptions de mouvement précises donnent à l'IA une direction claire.
Utilisez la vidéo comme teaser. Des clips courts et de haute qualité qui suggèrent plus génèrent de meilleures performances pay-per-view que des vidéos longues publiées librement. La vidéo est votre levier de contenu premium.
Générez en batch. Générez plusieurs variations de prompt pour le même concept en même temps. Cela vous donne des options et aide à identifier quels éléments de prompt produisent les meilleurs mouvements.
Prêt à ajouter de la vidéo à votre catalogue ? Les modules Text-to-Video et Image-to-Video d'OFGenerator sont disponibles depuis votre tableau de bord. Les nouveaux comptes bénéficient de 10 crédits gratuits.